
3D asset generation is getting massive amounts of attention inspired by the recent success on text-guided 2D content creation. Existing text-to-3D methods use pretrained text-to-image diffusion models in an optimization problem or fine-tune them on synthetic data, which often results in non-photorealistic 3D objects without backgrounds. In this paper, we present a method that leverages pretrained text-to-image models as a prior, and learn to generate multi-view images in a single denoising process from real-world data. Concretely, we propose to integrate 3D volume-rendering and cross-frame-attention layers into each block of the existing U-Net network of the text-to-image model. Moreover, we design an autoregressive generation that renders more 3D-consistent images at any viewpoint. We train our model on real-world datasets of objects and showcase its capabilities to generate instances with a variety of high-quality shapes and textures in authentic surroundings. Compared to the existing methods, the results generated by our method are consistent, and have favorable visual quality (-30% FID, -37% KID).
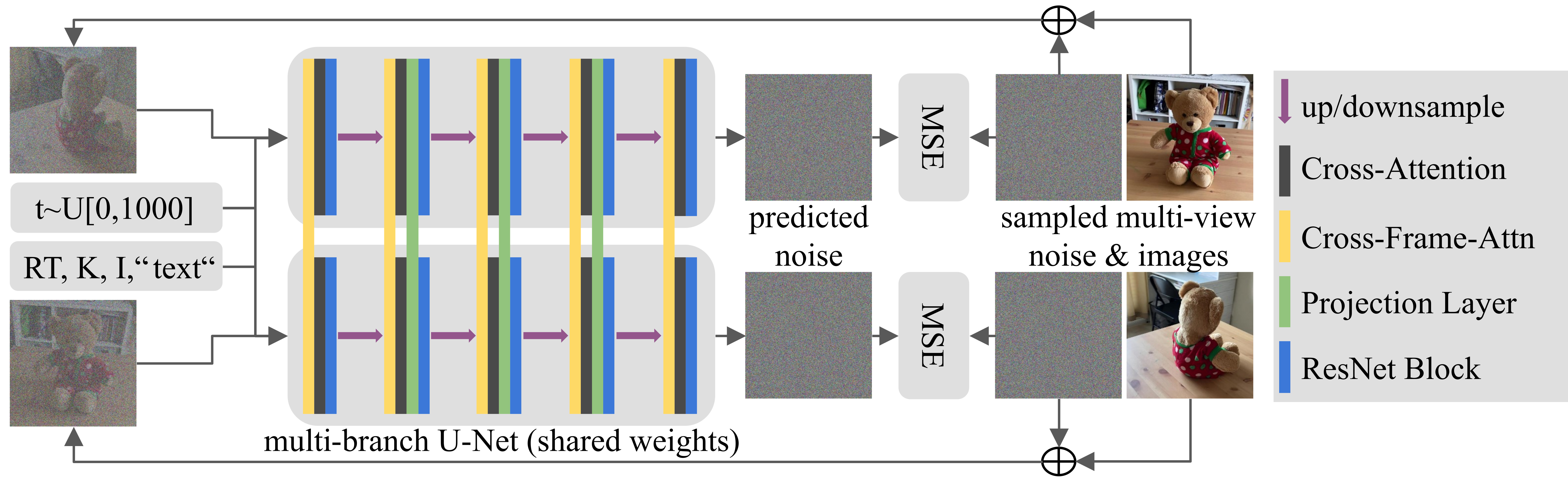
We turn pretrained text-to-image models into 3D consistent image generators by finetuning them with multi-view supervision. We augment the U-Net architecture of pretrained text-to-image models with new layers in every U-Net block. These layers facilitate communication between multi-view images in a batch, resulting in a denoising process that jointly produces 3D-consistent images. First, we replace self-attention with cross-frame-attention (yellow) conditioned on pose (RT), intrinsics (K), and intensity (I) of each image. Second, we add a projection layer (green) into the inner blocks of the U-Net.
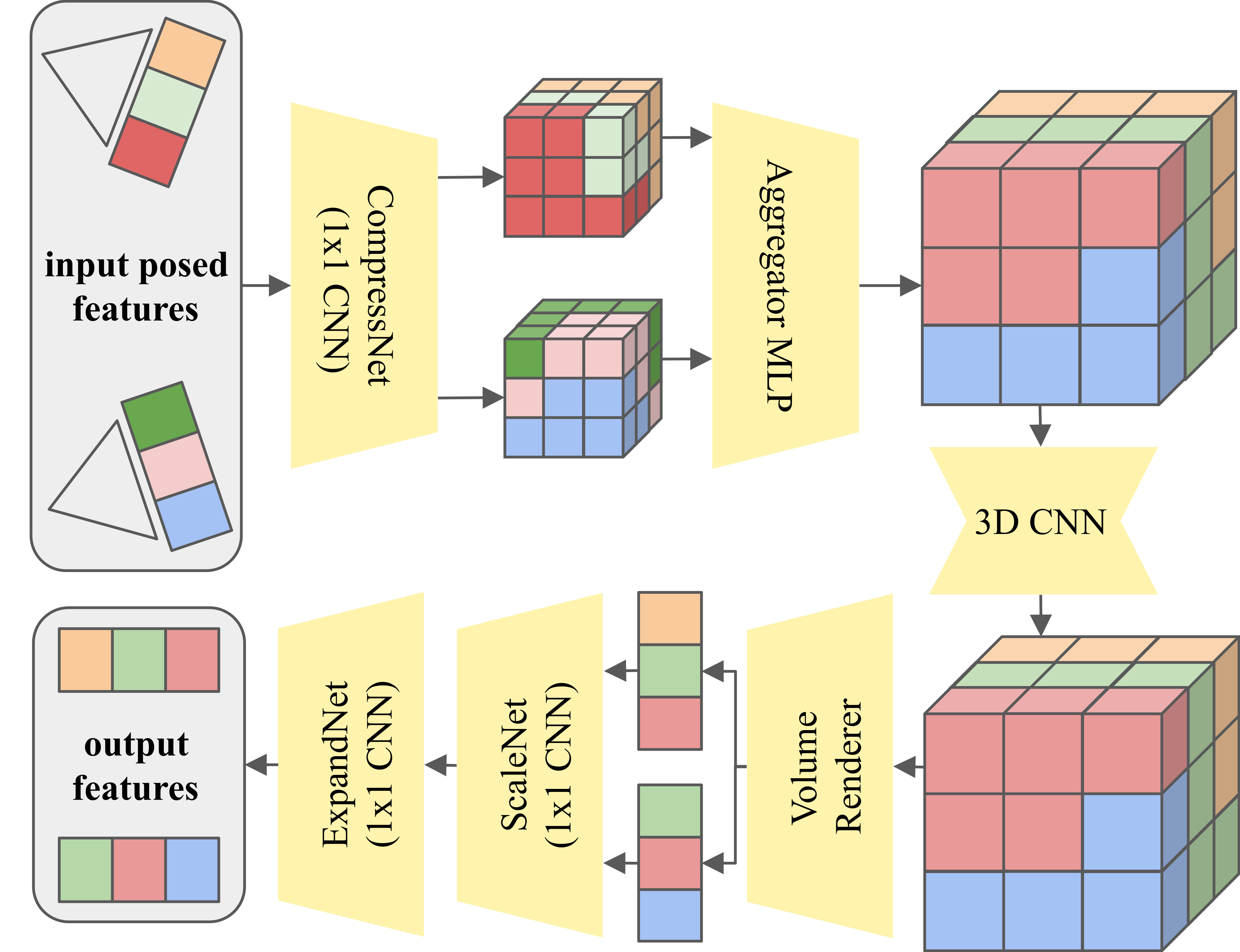
The projection layer creates a 3D representation from multi-view features and renders them into 3D-consistent features. First, we unproject the compressed image features into 3D and aggregate them into a joint voxel grid with an MLP. Then we refine the voxel grid with a 3D CNN. A volume renderer similar to NeRF renders 3D-consistent features from the grid. Finally, we apply a learned scale function and expand the feature dimension.
Given a text prompt and desired poses as input, we create multi-view consistent images of the same object in a single denoising forward pass.
Given a single posed image and desired output poses as input, we create multi-view consistent images of the same object in a single denoising forward pass.
We can combine text- and image-conditional generation to create more views of the same object in an autoregressive fashion. This allows to generate images in a smooth trajectories around a 3D object directly with our model.
@inproceedings{hoellein2024viewdiff,
title={ViewDiff: 3D-Consistent Image Generation with Text-To-Image Models},
author={H{\"o}llein, Lukas and Bo\v{z}i\v{c}, Alja\v{z} and M{\"u}ller, Norman and Novotny, David and Tseng, Hung-Yu and Richardt, Christian and Zollh{\"o}fer, Michael and Nie{\ss}ner, Matthias},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}