
We present Text2Room, a method for generating room-scale textured 3D meshes from a given text prompt as input. To this end, we leverage pre-trained 2D text-to-image models to synthesize a sequence of images from different poses. In order to lift these outputs into a consistent 3D scene representation, we combine monocular depth estimation with a text-conditioned inpainting model. The core idea of our approach is a tailored viewpoint selection such that the content of each image can be fused into a seamless, textured 3D mesh. More specifically, we propose a continuous alignment strategy that iteratively fuses scene frames with the existing geometry to create a seamless mesh. Unlike existing works that focus on generating single objects or zoom-out trajectories from text, our method generates complete 3D scenes with multiple objects and explicit 3D geometry. We evaluate our approach using qualitative and quantitative metrics, demonstrating it as the first method to generate room-scale 3D geometry with compelling textures from only text as input.
We iteratively create a textured 3D mesh from a sequence of camera poses. For each new pose, we render the current mesh to obtain partial RGB and depth renderings. We complete both, utilizing respective inpainting models and the text prompt. Next, we perform depth alignment and mesh filtering to obtain an optimal next mesh patch, that is finally fused with the existing geometry.
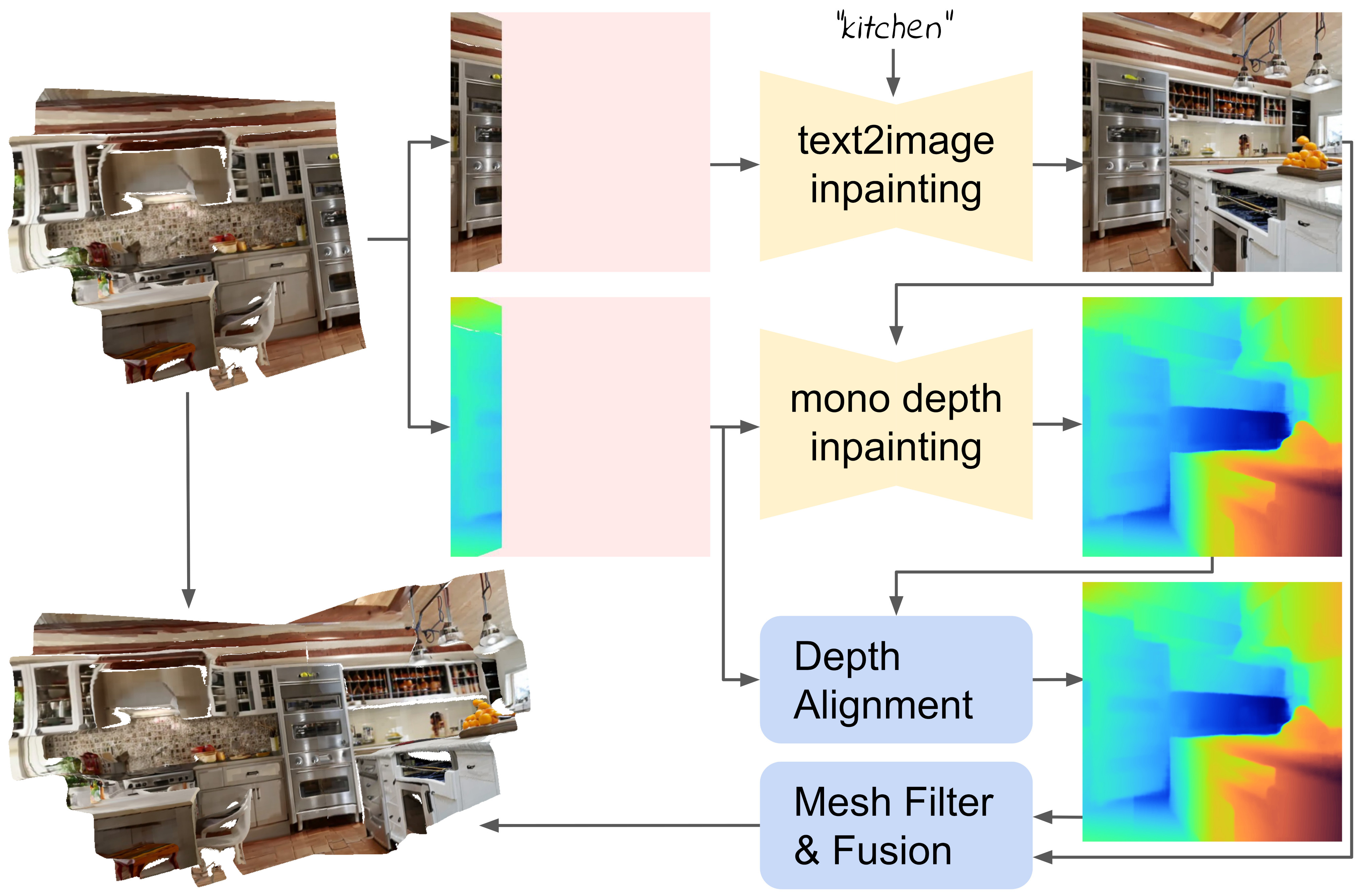
A key part of our method is the choice of text prompts and camera poses from which the scene is synthesized. We propose a two-stage viewpoint selection strategy, that samples each next camera pose from optimal positions and refines empty regions subsequently.

In the first stage, we create the main parts of the scene, including the general layout and furniture. For that, we subsequently render multiple predefined trajectories in different directions that eventually cover the whole room.
After the first stage, the scene layout and furniture is defined. Since the scene is generated on-the-fly, the mesh contains holes that were not observed by any camera. We complete the scene by sampling additional poses a-posteriori, looking at those holes.
A living room with a lit furnace, couch, and cozy curtains, bright lamps that make the room look well-lit.
@InProceedings{hoellein2023text2room,
author = {H\"ollein, Lukas and Cao, Ang and Owens, Andrew and Johnson, Justin and Nie{\ss}ner, Matthias},
title = {Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {7909-7920}
}